Red Hat Linux 5 - Installation
Red Hat Linux 5 - Installation
Step 1
– Insert the Red Hat Linux DVD into the DVD-drive of your computer. As
soon as the following screen pops up, press ‘Enter’ to install Red Hat
Enterprise Linux (RHEL) through GUI mode.

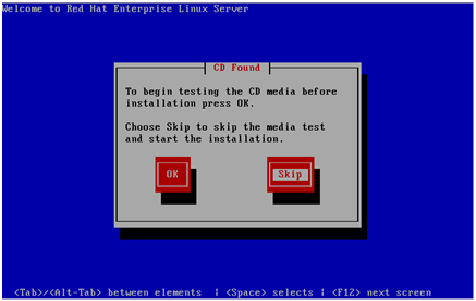
Step 2–
RHEL installer would then prompt you conduct a check as to whether the
CD media from which you’re installing is functioning correctly or not.
Choose ‘Skip’, press enter and the installation would begin.
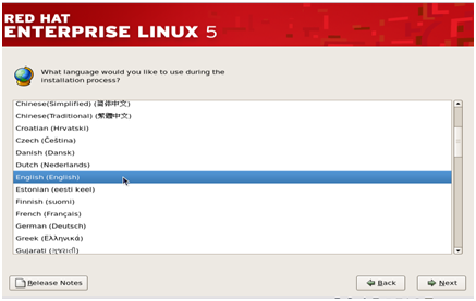
Step 3– Next, we need to select the language- English or any other language as per your preference, and then press ‘Next’ .
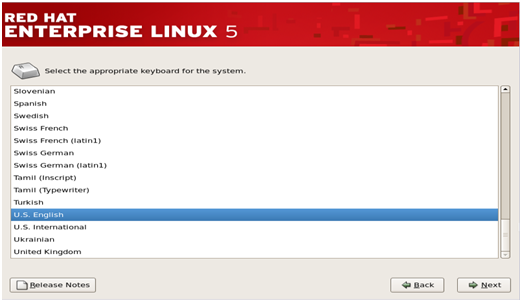
Step 4–
In this step, the RHEL installer would ask you about the appropriate
type of keyboard for the system. We take the ‘US English’ keyboard, you
can pick any other option depending on the type of your keyboard. Then
press ‘Next’ to move to the next step.
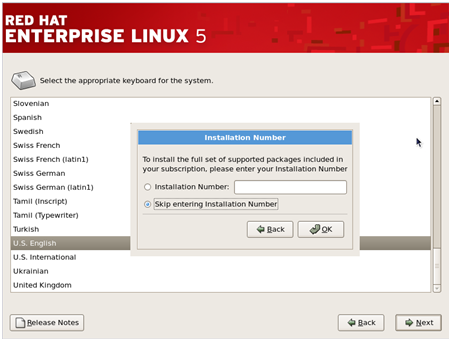
Step 5–
Next, the installer would ask for an ‘installation number’ if you wish
to install full set of Red Hat functionalities. Enter the installation
number and press ‘OK’ if you have an officially licensed installation
number(for corporate clients that buy Red Hat’s backup support and full
features).
Others
can select ‘Skip entering installation number’ and press ‘OK’ to
proceed. RHEL would show a warning message, press ‘Skip’ in it to
continue.
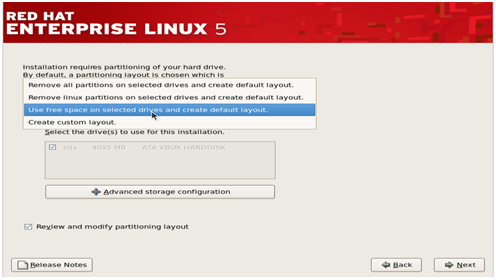
Step 6–
The Red Hat installer would then require you to create partitions in
your computer’s hard disk for the installation. You can do it in four
ways but the simplest way is to select ‘Use free space on selected
drives and create default layout’ as this option will not affect any
other OS residing in your system.
Check the ‘review and modify portioning layout’ to create partitions and click next.
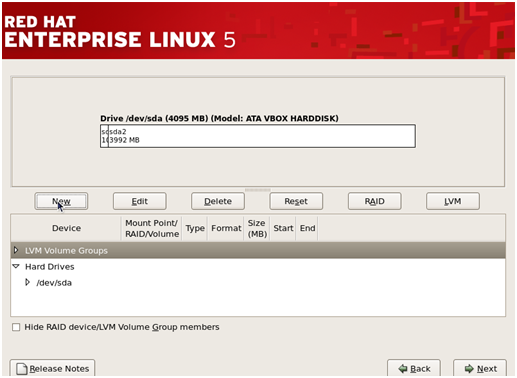
Step 7–
In this step you must create the required system partitions and mount
points such as ‘/boot’, ‘/home’, ‘swap’ etc which are required for the
Linux’s proper functioning.
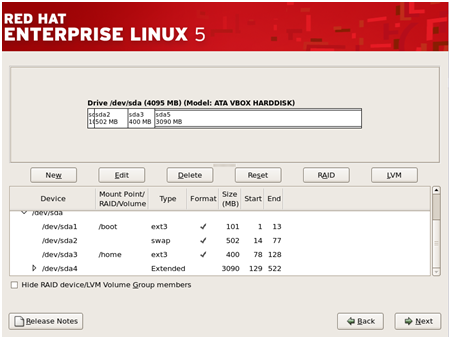
To create different partitions such as /home, /var etc, click on ‘New’ to create the partitions.
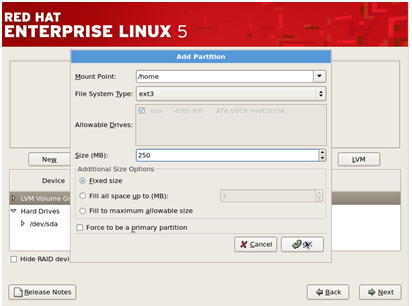
Then,
select /home in the mount point and choose ‘ext3’ as the file system
and give the desired size for it and then click ‘OK’. Similarly also
create /boot and /var.
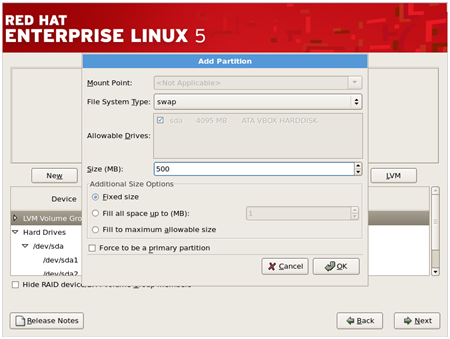
Also,
create a swap partition by clicking on ‘New’ and then choosing the
filesystem as ‘swap’ and also give the size of Swap partition.(Usually
size of swap partition SHOULD BE twice the size of RAM available to the
system but you can keep its size less than that too)
Once you have made all the desired partitions and given their mount points, click ‘Next’ to continue installation.
Step 8– This step pertains to the default OS that will be loaded by the GRUB loader
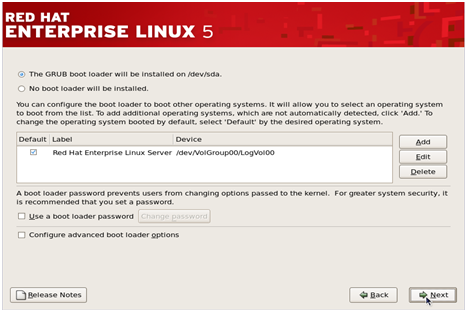
(Note-
If you have multiple Operating Systems installed, you would see
multiple options here and you have to check in front of the OS name that
you want to be loaded by default when the system is started.)
Click ‘Next’ to continue.
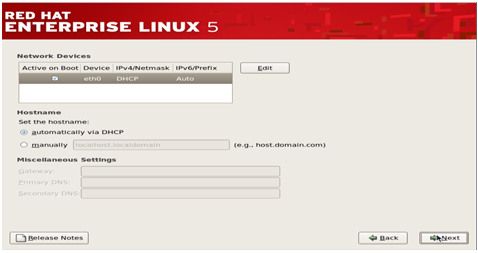
Step 9–
This step pertains to the network settings of the Linux system that you
are going to install. You can select the Ethernet devices through which
the system would communicate with other devices in the network.
You
can also provide the hostname, Gateway address and DNS address to the
system during this step. (However it’s better to adjust these settings
once the system has been fully installed).
Step 10– The next step is to adjust the system clock to your particular time zone. Select your time zone and then click ‘Next’.
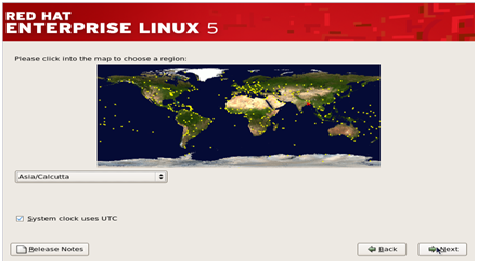
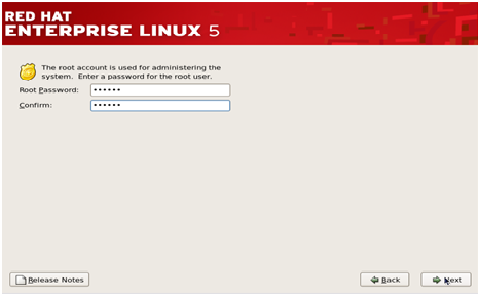
Step 11
– This is a very important step that deals with the root(super-user)
password for the system . Type the password and confirm it and then
click next.
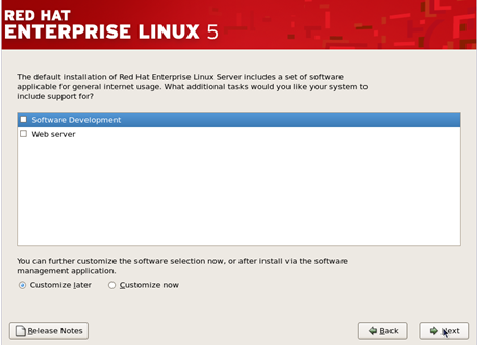
Step 12
– The RHEL installer would then prompt you about if you wish to install
some extra ‘Software Development’ or ‘Web Server’ features. By default,
keep it at ‘Customize later’ and press ‘Next’.
Step 13– This next step will initiate the installation of Red Hat Linux, press ‘Next’ to begin the process.

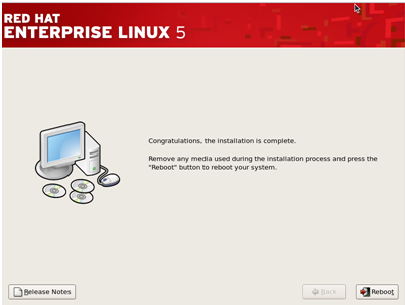
Step 14–
Upon the completion of installation you should the following screen.
Press Reboot and you’d be ready to use your newly installed Red Hat
Linux OS.
POST INSTALLATION CONFIGURATIONS
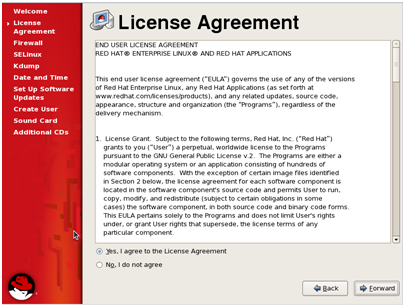
1. Accept the Red Hat License agreement and click ‘Forward.
2.
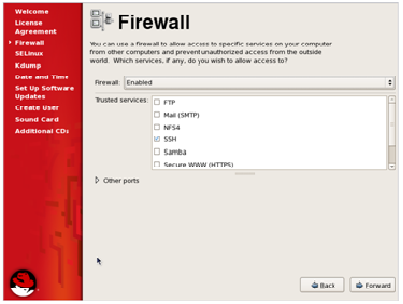
The next step is regarding the configuration of the Firewall. You can
Enable or Disable the firewall according to your preferences and then
click ‘Forward’.
3.
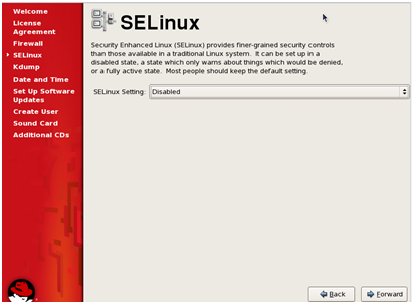
Next step is about the configuration of another security tool- SE
Linux. By default you should keep it ‘Disabled’ unless you’re working
with very secure information.
4.
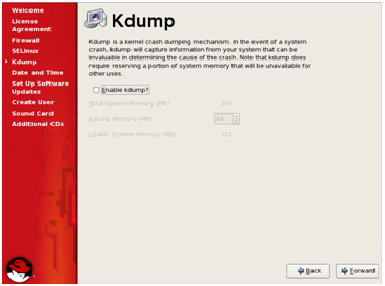
You can also choose to configure the Kdump, that stores information
about system crashes if your system fails but uses valuable disk space.
By default don’t enable it.
5. Next, adjust the time and date settings, and then click ‘Forward’.
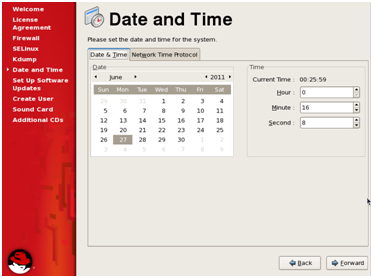
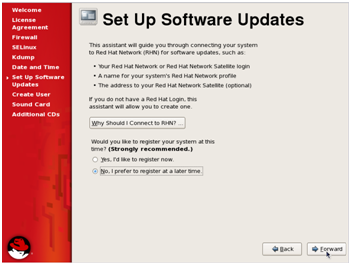
6.
The next step is for software updates from Red Hat, at this point you
should skip the registration and register at a later time and then click
‘Forward’.
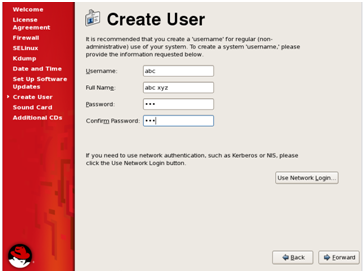
7. This step is to create a non-admin user for the system. Enter the details and click ‘Forward’.
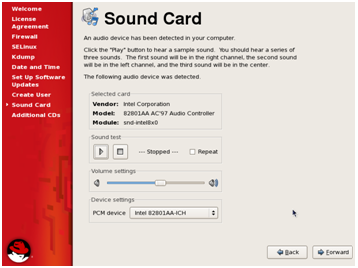
8. This step is about configuration of your Sound Card, choose a sound device and then click ‘Forward’.
9. Click ‘Forward’ to complete the configurations and start using your Red Hat Linux OS.
(Note-
On clicking ‘Finish’ the system would require a reboot if you have made
changes to the configurations of Firewall or SE Linux.)
Your
Red Hat Linux OS is now all installed and configured, ready to be used.
Good luck using and exploring various features of Red Hat Linux.